Ein Freund von mir hat vor vier Jahren mal ChatGPT benutzt, um eine Programmieraufgabe zu lösen. Der generierte Code sah auf den ersten Blick sauber aus, aber zwei Variablen in einem Funktionsaufruf waren vertauscht, was dann erst in der Produktion aufgefallen ist. Seitdem ist für ihn das Thema durch: KI taugt nichts.
Das ist die Geschichte, die er rausholt, wenn jemand anfängt von LLMs zu reden, und ich habe sie inzwischen oft genug gehört, um sie auswendig zu können.
Das eigentliche Problem war nicht der Code, sondern das blinde Vertrauen darin. Kein erfahrener Engineer reviewed einen API-Aufruf nicht, egal ob er von einem Menschen oder einem Modell kommt. Dass dieser Code durch die QA gerutscht ist, ist ein Prozess-Problem, kein KI-Problem. Mein Freund hört zu, nickt. Beim nächsten Gespräch kommt dieselbe Geschichte wieder. Er ist kein Einzelfall, er ist eigentlich Tech-affin, und genau das macht mich wahnsinnig.
Die Modelle von heute sind schlicht nicht die Modelle von 2021. Die Entwicklung war so schnell, dass ein fairer Vergleich kaum noch möglich ist. Wer auf Basis damaliger Erfahrungen urteilt, urteilt über ein anderes Werkzeug. Das wäre, als würde jemand sagen: “Ich hab vor vier Jahren mal einen schlechten Arzt gehabt. Medizin taugt nichts.”
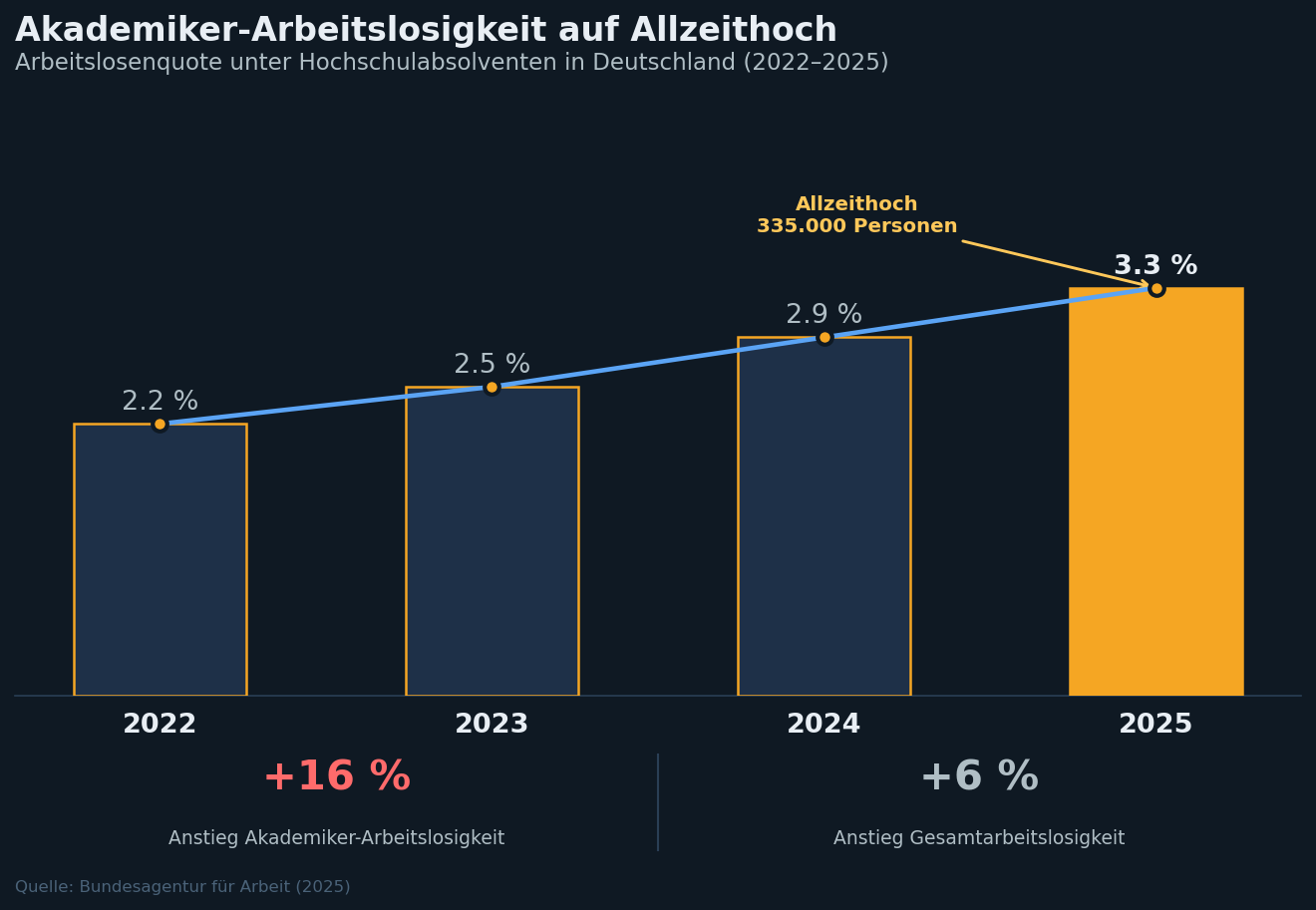
In Deutschland ist die Zahl der arbeitslosen Akademiker 2025 auf 335.000 gestiegen — ein Allzeithoch, wie die Bundesagentur für Arbeit meldet. Die Arbeitslosenquote unter Hochschulabsolventen kletterte von 2,2 auf 3,3 Prozent, 16 Prozent schneller als die Gesamtarbeitslosigkeit. Man kann darüber streiten, wie viel davon auf KI zurückgeht und wie viel konjunkturell ist. Aber auffällig ist, dass es genau die unteren Sprossen der Karriereleiter trifft: Einstiegsjobs mit klassischer Kopfarbeit, Standardanalysen, überschaubare Programmieraufgaben. Genau die Aufgaben, die LLMs heute routinemäßig übernehmen.
Was gerade passiert, geht aber über “KI schreibt Code” hinaus. Aktuelle Systeme können bereits eigenständig Teilaufgaben planen, Werkzeuge aufrufen und Zwischenergebnisse bewerten, ohne dass ein Mensch jeden Schritt anstoßen muss. Ein Analyst, der früher drei Stunden für einen Bericht gebraucht hat, konkurriert jetzt mit einem System, das dasselbe in Minuten liefert, iteriert, und auf Rückfragen antwortet. Das ist nicht Science-Fiction, das ist das, was ich täglich nutze. Und wer das auf Basis eines Bugs von 2021 beurteilt, wird das Tempo nicht aufholen.
Der klügste erste Schritt ist deshalb, aufzuhören, KI an kostenlosen Modellen zu messen, die oft ein Jahr hinter dem aktuellen Stand liegen. Wer die Frontier-Modelle nicht kennt, kennt KI nicht, so wie jemand der zuletzt 2015 ein Smartphone hatte nicht behaupten kann, zu wissen wie mobile Software heute funktioniert.
Wenn ich mit meinem Freund rede, geht es ihm eigentlich nie wirklich um diesen Bug. Es geht darum, dass er das Tempo nicht einschätzen kann und das Unbehagen lieber in eine alte Geschichte packt als in eine offene Frage. Das kenne ich. Aber die offene Frage lautet nicht: “Ist KI gut oder schlecht?” Die Frage lautet: Was will ich eigentlich erreichen, und wie verändert dieses Werkzeug, was davon jetzt möglich ist?
Wer diese Frage nicht aktiv stellt, beantwortet sie trotzdem. Nur eben passiv.